Thousands of Objects in a Graph
Printed From: MetaCase
Category:
Forum Name: MetaEdit+
Forum Description: All topics relating to MetaEdit+ or DSM
URL: https://www.metacase.com/forums/forum_posts.asp?TID=118
Printed Date: 27.Mar.2026 at 05:33
Software Version: Web Wiz Forums 12.05 - http://www.webwizforums.com
Topic: Thousands of Objects in a Graph
Posted By: sap630
Subject: Thousands of Objects in a Graph
Date Posted: 22.Sep.2009 at 08:39
|
Supposing we have 5000 objects called "object_type_1" linked to 10000 objects called "object_type_2" in one graph (picture one very large ERD where object_type_1 is entities, and object_type_2 are attributes). What options are available to view all this information section by section (i.e. small subsets)? Is it possible to link relationships across seperate graphs instances? If I now create a new object_type_1 object in the graph (5001 object_type_1's now exist), and I need to Connect it to specific object_type_2 objects that already exist; is there a way to filter the 10000 objects based on their name property? |
Replies:
Posted By: stevek
Date Posted: 22.Sep.2009 at 11:50
|
Technically, you could have one graph (conceptual information, abstract syntax) with several diagrams (representational information, concrete syntax). The conceptual graph has 15000 objects, but each diagram only shows say 50 of them. In each diagram you'd have visible the objects you want in that diagram, plus any others from other diagrams that you want to see relationships to. You can use the right-hand column of the Graph Browser in the main MetaEdit+ window to filter the objects based on their name property and type, and copy and paste the desired object_type_2 from there.
A better approach would be to decompose your graph of 15000 objects into sensible units. Studies of human cognition show that we simply can't work well with such a large number all in one graph, even if we filter or use views. But if we break it down into subgraphs/modules, each of which can be considered at a higher level as its own unit, we can cope fine. You'll probably end up with 3 levels of graphs: 1 top-level graph with 20 "module" objects, each of which decomposes to its own graph with 20 "module" objects, each of which decomposes to a normal graph with 10-15 object_type_1 and 20-30 object_type_2 instances. An alternative would be 4 levels, with 7-8 module objects rather than 20 - or then a combination, 3 levels deep in some places and 4 in others.
Aim for modules with high cohesion (the objects in there make sense together and interact with each other) and low coupling (minimum number of relationships across subgraph boundaries). To make a relationship from an object A in one subgraph to an object B in a different subgraph, you can simply reuse object B in the first subgraph. Alternatively, you could have a new object type object_type_2_ref, with a single property that points to an object_type_2. In either case, you can open the Info... dialog of the object_type_2, to find out in which graph it is defined.
With 15000 objects you probably also need to think about integrating the work of multiple users. The multi-user repository of MetaEdit+ makes this easy and transparent, so all your users can work together - much simpler than trying to merge and reconcile multiple independent edits with an old-fashioned textual version control system.
|
Posted By: sap630
Date Posted: 23.Sep.2009 at 11:56
|
Thanks Steve. Any chance you have a MXT file describing the CWM (Common Warehouse Metamodel) specification? Also, any XSLT to convert CWM models into MXM files? |
Posted By: stevek
Date Posted: 23.Sep.2009 at 13:18
|
Sorry, we don't have an MXT file for CWM. The CWM XSchema is over 1MB, 74 packages, 470 classes. As with all XSchemas, it's massively underspecified for use as a metamodel, so there's no way to automatically make a good MetaEdit+ metamodel for it. Instead, you need to understand what they intended, and make your own decisions about what makes a good modeling language for human use, as opposed to just being able to store the data.
Experience shows that a MetaEdit+ metamodel to contain the same information as an OMG XSchema is much smaller and easier to understand - much of the bloating of OMG schemas is due to the unsuitability of MOF to describe metamodels and of XMI to store them.
If you don't need full CWM compatibility, but just to import an existing data set, I'd suggest making your own metamodel based on the needs of your domain. You can then build a naive text-to-model transformation that is able to read just what is in your existing data set, and build the MXM file you want. That's a couple of orders of magnitude faster than trying to make a full, bulletproof XSLT and MXT for CWM. And remember that even if you had the full versions, the chances of being able to import correctly from all other tools that claim CWM support are slim indeed (cf. http://www.metacase.com/blogs/stevek/blogView?search=XMI&searchTitle=true&searchText=false - XMI for UML ).
|
Posted By: sap630
Date Posted: 15.Oct.2009 at 23:55
|
Is it possible for one meta-meta-model enforce the design of a meta-model, which enforces the design of a model?
e.g. The ERD in Examples. |
Posted By: stevek
Date Posted: 16.Oct.2009 at 00:13
|
I'm not sure I understand your question, but I'll try and answer.
The meta-metamodel in MetaEdit+ is GOPPRR, which is fixed. You can use the metamodeling tools to define your own metamodel, as we did when building the ER metamodel. Having done that, you can use the modeling tools to build your own models, as we did when building the example ER diagram "Orders and Products". The model conforms to the metamodel, and the metamodel conforms to the meta-metamodel.
If you are envisaging multiple layers of people who can "enforce the design" of the next level down, that can work well too. You don't need extra meta-levels, though. For instance, you can make a base metamodel and give that to a few other metamodelers, each of whom can make extensions to it (in accordance with your instructions of what they are allowed to add, change, subtype etc.). Each extended metamodel can be given to a group of modelers, who can make models that will conform to that extended metamodel - and also to your base metamodel (insofar as your instructions require).
We also have customers who partly automate the process of extending a metamodel, to make sure that the middle level of metamodelers only follow the top level's instructions, or simply to make it easier for the middle level.
As we did in the http://www.metacase.com/support/45/manuals/Graphical%20Metamodeling.pdf - graphical GOPRR modeling language, you can also build a modeling language whose domain is "modeling languages", and which generates the MetaEdit+ http://www.metacase.com/support/45/manuals/mwb/Mw-7_4.html - metamodel XML import format, MXT files. By drawing a model and pressing the Generate button, you can thus create a metamodel. Your metamodeling language could be similar to GOPRR or completely different: the only requirement is that it generates valid MXT files.
|
Posted By: sap630
Date Posted: 31.Oct.2009 at 15:02
Fascinating; dunno how I missed that manual. The Family Tree example is all about metamodeling the concept of a family trees. but using the individual tools (graph tool, object tool, etc). I had no idea that the GOPPR project along with the link you gave me would make meta-metamodelling easier! It didn't click that Figure 1-3 from the Evaluation tutorial: 
can actually be used in the GOPPR project, of which you can then Export and Build. Here is a broad description of our current process in a typical data warehouse environment:
Database design in steps 2 and 3 is done visually (MDA development) with automatic code generation. Extract-Transform-Loads (ETL) is also done visually with automatic code generation using another tool. The current tools are powerful in what they do best. Our biggest problem, however, is that all our metadata is scattered everywhere, so we are investigating the use of a central repository such as Apache Jackrabbit (or the commercial version called CRX). In addition to having a central metadata repository, we would need:
As such, I am trying to determine if MetaEdit+ would be an ideal tool for:
Also, wondering if there are any plans to open up the MetaEdit+ repository into a more JCR (Jackrabbit/CRX) like repository? |
 stevek wrote:
stevek wrote:Posted By: stevek
Date Posted: 02.Nov.2009 at 13:38
|
So what you need is a modeling language for describing database schema and ETL transformations. It will have concepts like Table, Column, and various ETL operations, e.g. Split to split a string value based on a separator character.
You can then build models of your databases and transformations, e.g. in the first RDBMS is a Table "Employee" that has a Column "Name"; in the second RDBMS is a table "Personnel" that has Columns "First Name" and "Last Name"; and between them is an ETL transformation that uses a Split from "Name" with the first part (role) going to "First Name" and the second to "Last Name":
/----first---> "First Name"
"Name" ----- "Split on: space"
\---second---> "Last Name"
Hopefully it is obvious this is a simplification! The main thing I wanted to make clear is how the various meta-levels would work. That will stay the same whether you have one column or 50 000, and whether you have a simple modeling language or a complex one. You can extend the modeling language as you go, as you mention in point 3 above.
By modeling all this in MetaEdit+, you can solve the problems you currently face by having several tools. If you change "Last Name" to "Surname", you don't need to find the places in both your ER tool and your ETL tool where that is referenced: you just change it once in the model in MetaEdit+, and that change is visible in both the schema models and the ETL models. I'd probably have separate Graph types for schema modeling and transformation modeling, with the Column type used by both. The schemas define the Column objects; the transformations use them. You can have multiple users working in the same MetaEdit+ repository - some building schemas, some building transformations, maybe someone extending the modeling language. Versioning and locking happen at the level of objects, so you can work together without the tool getting in the way.
You can write generators to check the things you need to ensure, e.g. that every column in the target database is mentioned on the RHS of some ETL rule, and that the ETL rules only reference columns that are actually in the respective tables. You can make the warnings from those checks show up when you want, e.g. only when doing a build, or instantly in the diagram if a modeler tries to connect an illegal column (e.g. makes the mapping backwards).
You can also write generators to produce the SQL that creates the schemas in your first and second databases, and the ETL script (whatever format your ETL engine needs). If you prefer, you can export models so your existing ER and ETL tools can open them (exporting to XML and transforming with XSLT, or writing a generator to create a text format readable by the tools, or using the MetaEdit+ API to access the model data directly).
As for Jackrabbit: to be honest, I don't think just having all the models (i.e. your "metadata") in one content repository is enough of a solution. That just puts it in one place; you can do that by putting your current ER and ETL files on the same hard disk! The big question isn't where it is, but are there tools to access it and know what it means (i.e. that a Column is defined in the schema and used in the ETL). With MetaEdit+, you get the repository and the tooling.
|
Posted By: Luc
Date Posted: 05.Nov.2009 at 03:40
|
Steve - our application has the equivalent of thousands of database tables, tens of thousands columns, two thousands screens/web pages, tens of thousands of fields, etc. Starting from any one of these objects we generate source code for our application. For example, starting from a database table definition we generate DDL and database access methods. From a screen definition we generate validation rules for each updatable field on the screen.
These objects are linked to each other, thus a screen field is linked, via an intermediate abstract object we call "element", to database columns. (Maybe we could have modelled our metadata differently - however that is what we have now). The object type "element" contains the specifications of each data item, whether a database column, screen field, attribute in an xml message/document. These specifications contain the usual data type information, plus lists of domain values and their representation on different media - for example for an element called "maritalStatus" a domain value would be "single", and its representation might be "SIN" for storage on the database, "Single" for display on a web page or screen, and its xmlName might be "mst".
Now, suppose we have a separate graph for each database table, and a separate one for each screen or web page, since these graphs all connect via the element objects, how do we avoid replicating the information from the elements into the two types of graphs?
Further, in another view we might want to draw an ER diagram of the tables. It is true that it is not useful to graw an ER diagram containing thousands of tables, so it does make sense to group the tables somehow. However, this does not remove the need for a table in one group to be linked to another table in a different group. So, how would we deal with the situation where we need to draw a model of that particular link and neighbouring tables?
Thus, we have hundreds of thousands of metadata objects interlinked in various ways. We were wondering if it would be possible for a user to select an object, say a particular database table, and for metaEdit+ to draw a particular type of graph relating to the table, its columns and the elements? And, in another use-case, for metaedit+ to draw a different graph, eg an ER diagram centred on that table, but containing adjacent tables, perhaps one or two or three steps away?
Thanks
|
Posted By: stevek
Date Posted: 05.Nov.2009 at 13:10
|
Luc - having the "maritalStatus" element in many graphs, even of different types, is no problem for MetaEdit+. In fact, it's what MetaEdit+ does best! The same object can be in many graphs: it's not a copy or duplicate, it's the same identical object. Graphs point to their objects, rather than strongly containing them: many graphs can point to the same object.
Similarly, objects can point to other objects. This allows you to create references, so you don't need to directly include a 'foreign' object in a graph, but can have a different type of object directly in the graph, and have that object point to the 'foreign' object. In your ER diagram example, that's one way of modularizing your database: try and keep most links between tables internal to the module containing those tables, but allow links to tables in other modules via these reference objects. Of course nothing stops you from directly including the elements from outside the group if you want; it's just often easier for modelers to understand if you make explicit which links are considered internal and which external.
As you say, the exact choice of how to model and link screen fields with database tables is an open question. At the small/new/simple end of the scale, people make the screen fields primary: they just want to model the UI and have the database automatically generated. At the large/legacy/complex end of the scale, people make the database primary: the schema exists and is largely fixed, and when you create a UI field you need to link it to some existing database column. Somewhere in that scale is the best solution for your needs, and we'd be happy to help you find that.
As to generating graphs on the fly, that's certainly possible. The MetaEdit+ generators can produce new graphs in MetaEdit+'s Model XML format, and import those for the modeler to see. Reading a new graph however is hard on the human brain, a bit like a map to an unfamiliar town, or even worse a familiar area where all the towns have been rearranged into different positions. As far as possible I'd thus aim to make the existing models naturally answer the questions the modelers are likely to want to ask - that's largely a question of creating the right metamodel, e.g. one with extra concepts to better cope with questions of large scale (compared to ER diagrams).
Tooling helps here too: e.g. you can select any object in a graph and ask for its Info, which will show you all the other graphs where it is used and allow you to jump directly to that object in those graphs. Another nice feature of MetaEdit+ is the generation of reports that are linked to objects: e.g. you could create reports that would show the information that the modeler would want, and he can then double-click the text of the desired object in the report output and jump straight to that object in the model. These features are really useful when you want to explore a large model.
|
Posted By: Luc
Date Posted: 05.Nov.2009 at 15:01
|
Thank you Steve, that is very interesting. It had not occurred to us that one could use MetaEdit+ as a repository as well. In fact, although your web site does mention there is a repository, I could not find any information about what its capabilities are. This is why my colleague asked the question about Jackrabbit.
We will continue experimenting with MetaEdit+ to see what is possible. I have many questions that I need to ask: here is a curly one - say we use MetaEdit+ to generate some Java code. Is it possible for MetaEdit+ to capture the generated Java code and store it inside (or elsewhere but under the control of) the repository as another object? Naturally there ought to be metadata associated with it - eg the type of module - class, method, etc, but also more interestingly, a reference to all the other metadata objects that were referenced during the code generation process - such that if one of those objects changes then we can tell that we need to regenerate the Java module, and also which code generator to use. And this needs to be supported by a powerful versioning system - which is a whole discussion in its own right.
wrt the question about CWM, the reason is that we use tools like ERWin plus others associated with the data warehouse and BI processes. These tools can import/export CWM models. If we want to integrate or link all these models we need to place all the metadata into a central repository, which as a consequence must be able to receive and send CWM models. Would we be able to use the Metacase repository to store all this metadata, and would we be able to import/export the metadata relatively easily without loss of information?
Thank You
Luc.
|
Posted By: stevek
Date Posted: 06.Nov.2009 at 14:22
|
It's probably best to think of the MetaEdit+ repository as just for the models (and their metamodels). If you want to share data via CWM with other tools, writing the exporter generator would be easy for you. As you'll understand, there can't be a generic CWM exporter in MetaEdit+, because what it should do is entirely dependent on the metamodel you come up with. Similarly for writing the importer, as I mentioned before (although then I was thinking of a CWM metamodel, rather than a combined "ER + ETL + extra metadata" metamodel). There's nothing to stop you capturing generated source code into models, but I wouldn't advise it. If you want the generated Java source, you should also have the compiled bytecode
|
Posted By: Luc
Date Posted: 09.Nov.2009 at 16:48
|
Steve, thank you. I guess we have a fair amount of experimentation to do.
Meanwhile, do you have any documentation about the capabilities or specifications of the repository?
Thanks, Luciano
|
Posted By: stevek
Date Posted: 10.Nov.2009 at 14:11
|
For an understanding of what the repository is, its capabilities, and how it works in MetaEdit+, see the following sections in the MetaEdit+ User's Guide:
http://www.metacase.com/support/45/manuals/meplus/Mp-2_2.html#Heading184 - 2.2 MetaEdit+ — a brief introduction
http://www.metacase.com/support/45/manuals/meplus/Mp-6_1.html#Heading1544 - 6.1 Object repository
To learn more technical details and how to be a "DBA" for the repository, see the http://www.metacase.com/support/45/manuals/sysadmin/sa.html - System Administrator's Guide .
If you're interested in the possibilities of integrating MetaEdit+ and its repository with your wider tool environment, see our section on http://www.metacase.com/mwb/integration.html - integration and Chapters http://www.metacase.com/support/45/manuals/mwb/Mw-5.html#Heading858 - 5 , http://www.metacase.com/support/45/manuals/mwb/Mw-6.html#Heading1937 - 6 , http://www.metacase.com/support/45/manuals/mwb/Mw-7.html#Heading1981 - 7 , http://www.metacase.com/support/45/manuals/mwb/Mw-8.html#Heading2326 - 8 and http://www.metacase.com/support/45/manuals/mwb/Mw-9.html#Heading2677 - 9 in the MetaEdit+ Workbench User's Guide.
And if you want some numbers:
maximum number of objects per project: 4,294,967,195
maximum number of projects per repository: theoretically unlimited |
Posted By: sap630
Date Posted: 11.Nov.2009 at 03:50
Hi Steve, Following from the above quote and the section on Versioning: http://www.metacase.com/support/45/manuals/sysadmin/sa-2_4_1.html#Heading278 - http://www.metacase.com/support/45/manuals/sysadmin/sa-2_4_1.html#Heading278 What would happen to "object_type_2_ref" if the model in which object_type_2 exists is versioned? Will the reference be to the frozen version, or updated to the current one? |
Posted By: stevek
Date Posted: 11.Nov.2009 at 11:53
|
If you use a direct reference, as in object_type_2_ref above, your object_type_2_ref will always continue to point to the original object_type_2, i.e. the one now considered frozen.
If object_type_2_ref is reachable from the model that you export, you will also end up with a new copy of object_type_2_ref, which will point to the new copy of object_type_2.
If you want something like object_type_2_ref, but which always points to the latest object_type_2, you need to make a more indirect link. The most obvious way to do that is to use string equality: type the name of object_type_2 in a string property of object_type_2_ref. This gives you all the pros and cons familiar from textual programming languages, e.g. where you type the name of a function when you define it, and again each time you call it or otherwise refer to it: you get an extra layer of indirection, but are responsible for updating the name in object_type_2_ref if you rename your object_type_2.
For more on versioning, see our http://www.metacase.com/support/45/documentation/versioning.html - short white paper on versioning , or Chapter 15 in the http://dsmbook.com/ - Domain-Specific Modeling book . It's clearly a large topic, and equally clearly changes totally when the artifacts in question are networks of directly linked objects rather than separate text files with only indirect, string-based references between them.
|
Posted By: sap630
Date Posted: 13.Nov.2009 at 04:07
|
Cheers for the info & extension, tested the versioning a bit. I can understand why "the versionable unit
is a repository" according to the whitepaper. Going onto the topic of dynamically drawing models (i.e. automating the model drawing process): I was going through the http://www.metacase.com/papers/importing_API.pdf - import API paper , and http://www.metacase.com/support/45/manuals/mwb/Mw-8_2.html#Heading2578 - watch example API code and noticed that both use the instProps() method followed by addToGraph(). How would you go that one step further and add the representation of the new_object in the diagram? From what I can tell, it would appear that you need to utilize addNewObjectRepFor(), along the lines of: ... port.addToGraph(newObject, graphs[0]); // Going one step further and adding the "newObject" to the diagram: com.metacase.MEOop[] diagrams = port.diagrams(graphs[0]); MEAny place_position = new MEAny(); place_position.setMeType("Point"); place_position.setMeValue("600,150"); port.addNewObjectRepFor(diagrams[0], newObject, 1, place_position); However, it fails with an exception (that is difficult to decode). Not exactly sure what "1-based integer" refers to actually  so put 1. so put 1. |
Posted By: rise
Date Posted: 19.Nov.2009 at 16:56
|
A fix for this representation creation problem via API is now available on our support web site: ../support/45/program/#reprCreationAPI - http://www.metacase.com/support/45/program/#reprCreationAPI Download the reprCreationAPI.mep patch file and apply it as usual: 1) Create a folder called 'patches' in your MetaEdit+ working directory (c.g. C:\Documents and Settings\user\My Documents\MetaEdit+ 4.5\patches) 2) Copy the .mep patch file into this folder 3) Modify the Target in MetaEdit+'s start icon's properties to include command line argument 'fileInPatches' (i.e. "C:\Program Files\MetaEdit+ 4.5\mep45.exe" fileInPatches) 4) Start MetaEdit+ from the icon. When starting, the program will now check the contents of the 'patches' folder and load all patches found from there. 5) Have fun with MetaEdit+ :-) As for the question about 1-based integer, it is just an index for representation element's position in Z-order. 1 denotes the backmost element, so passing it as an argument would create the new representation behind everything else. If you want to place your new element topmost in the Z-order, use 0 (this 0-option is a new feature provided by the aforementioned patch, so it doesn't work without it). |
Posted By: sap630
Date Posted: 20.Nov.2009 at 00:03
|
Thanks, patch works well.
The term "0-based integer" or "1-based integer" was difficult to decode because generally we are used to thinking of numbers in terms of "base 10 (decimal)", "base 2 (binary)", "base 16 (hex)" ... etc. As such base 0, or base 1 integers makes no sense.
Eventually figured out that a "0-based integer" is referring to an indexing method similar to the array indexing in Java, C or C++ whereby the first element of an array is indexed by integer 0 (e.g. my_array[0]). Whereas, other languages might start from 1, and so are "1-based integers".
Terminology sure is strange and a google search for definitions of "0-based integer" or "1-based integer" wasn't exactly helpful.
Had a good laugh about it.
|
Posted By: sap630
Date Posted: 02.Dec.2009 at 08:22
|
Hi Steve, With MetaEdit+ it is possible to have something like:  To accomplish this requires that the "Entity_With_Attributes" object simply contains Properties which are of Data Type "Object" (either entity or attribute). However, since there can be any number of attribute objects, the "Entity_With_Attributes" object requires a Property which is a list/array of Attribute Objects. I cannot seem to create such a list of Attribute Objects as a property. Any ideas? |
Posted By: janne
Date Posted: 02.Dec.2009 at 08:54
|
Hi, Please try following: 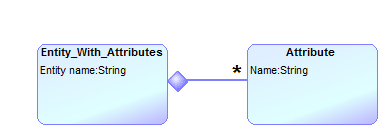 Or by using the form based metamodeling tools structure like: 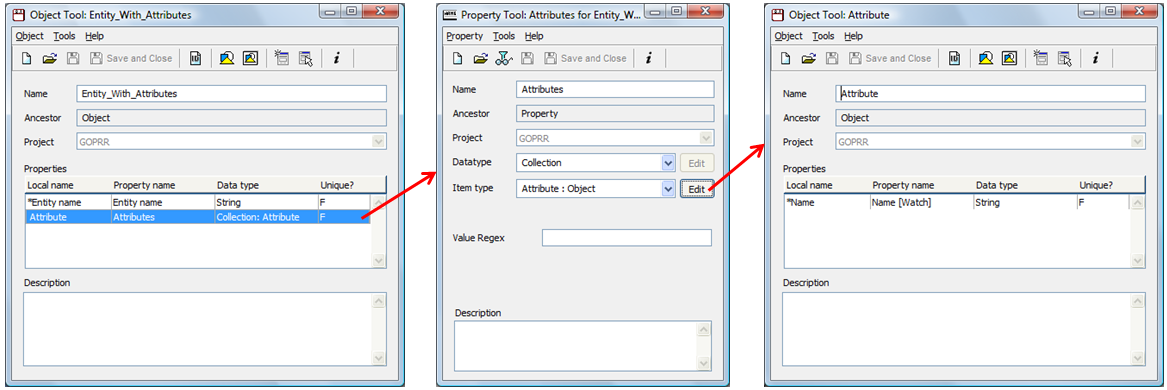 |
Posted By: stevek
Date Posted: 02.Dec.2009 at 12:03
|
I'm not sure Janne answered your question, so I'll have a go too. Pick whichever answer you like :-).
It's generally not a good idea to make Datatype or Item type = Object, because that would allow absolutely any kind of object. If you need to do it, hold shift down while opening the dialog from which you choose the object type, and Object will magically appear in the list. The best way is probably to make a common supertype of Entity and Attribute, and mark it as abstract (start its name with an underscore), e.g. _Content. The property type then has Datatype = Collection and Item type = _Content. Looking at the names you use and the examples, I wonder if you might actually want something else. If Entity_With_Attributes only ever has one Entity, then make that a separate property, of Datatype Entity, and you can have the second property, a Collection of Attirbutes, without needing to allow contents of different types.
Alternatively, if what you really want is to draw the Entity_With_Attributes as a big box that contains attributes, you may want it not to have properties, but to simply visually contain the Entity and Attribute objects that you put in the graph. You can then use the MERL commands, contents and containers, to access this information both for rules (making the symbol show an error if the enclosure is wrong) and generation.
What is the semantics of ER diagram (type B)? And why do you want two different graphs showing the same thing (in this example at least)? Think about whether the objects in the lower graph are identical to those in the upper graph, or are themselves new objects that refer to the objects in the upper graph. Think about whether you can use 'convention over configuration', e.g. if the default situation is that a Type A graph has a roughly isomorphic Type B graph, then you don't need to draw the Type B graph, since it adds no information: you can already generate what you want directly from the Type A graph.
|
Posted By: sap630
Date Posted: 03.Dec.2009 at 00:44
Thanks Steve and Janne - "Collection" was the key.
^ This was what I was after. But I can see how the first thing you mentioned would also work:
Where you mention:
Correct, however, the problem isn't generation but modeling without cluttering the screen. As the thread title mentions, we would eventually have thousands of objects in a low-level graph (similar to subgraph of type A) with "chunks" or "views" of those objects as groupings in another subgraph (similar to subgraph of type B). We would like the modellers using the type B subgraph to have direct access to the underlying object from the type A subgraph (to avoid duplicating information). Cheers. |